什么是图数据库
维基百科定义:
在计算机科学中,图数据库是一个使用图结构进行语义查询的数据库,它使用节点、边和属性来表示和存储数据。
图数据库并非是存储图片的数据库,而是面向或基于图的数据库(与其底层存储方式有关),属于非关系型数据库,即NoSQL的范畴。
它直接将存储中的属性、节点和节点间表示关系的边相关联。这些关系允许直接将数据链接在一起,并且在很多的情况下可以通过一个操作进行快速搜索。
图数据库的优势: 可以简单快速的检索多层次关系系统中复杂的关系数据。例如在社交网络关系中快速的查询到N度人脉数据,就可以在图数据库中实现快速检索,如果在关系型数据库上实现,其查询效率可能会极低。
图具备以下的特征:
- 包含节点和边
- 节点和边上均可以用拥有自己的属性
- 边有名字和方向,并总是有一个开始节点和一个结束节点
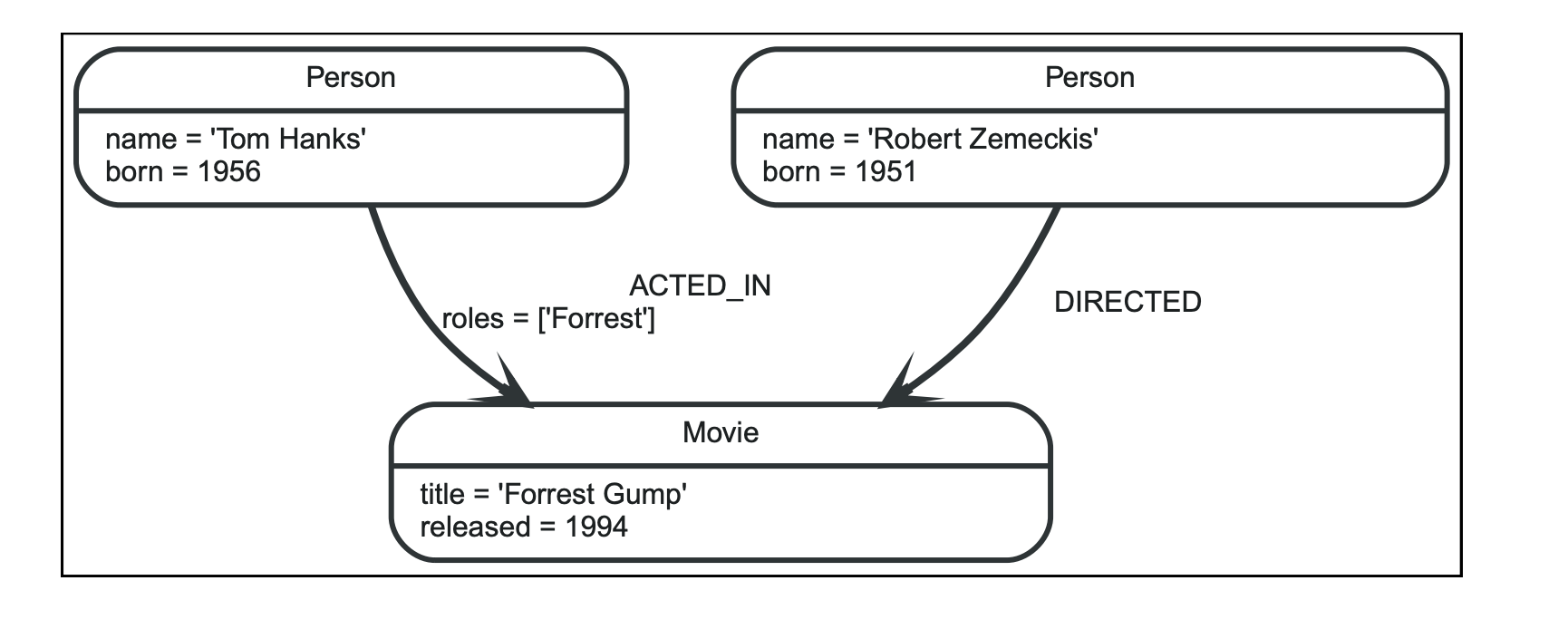
如下截图可以直观看出其特征:
- 两个Person节点、一个Movie节点
- 每个Person节点拥有name和born属性,Movie节点拥有title和released属性
- 其中一个Person与Movie之间的关系是DIRECTED,另一个Person与Movie之间的关系是ACTED_IN
- ACTED_IN关系中拥有属性roles
图数据库的常用领域:
- 社交网络:管理社交关系,实现好友推荐
- 推荐和个性化:实现商品实时推荐
- 欺诈识别:银行欺诈,信用卡欺诈等
- 金融领域:用图数据库做风控处理
- 汽车制造领域: 依靠图数据库推动创新制造解决方案
- 电信领域: 依靠图数据库来管理网络
当面向一个更复杂的关系网络中,就会突显图数据库的作用,例如你需要在以下的网状关系中找到与某个节点存在某种关系的其他节点,你会采用什么方式实现?

Neo4j介绍及基础使用
Neo4j介绍
简单介绍Neo4j的特性:
| 特性 | Neo4j |
|---|---|
| 是否开源 | 社区版开源,企业版收费 |
| 技术特点 | 一站式服务、工具齐全 |
| 查询语言 | Cypher |
| 开发语言 | Java |
| 集群 | 企业版支持,社区版不支持 |
| 量级 | 轻量级 |
从上面的特性可以看出,如果需要在生产环境使用Neo4j,为了保证可用性需要使用付费的企业版。社区版并不支持集群模式,除非自己实现双读双写的HA逻辑。但其一站式服务和工具极大的降低了使用上手的成本,并且提供了成熟的UI客户端,提供多语言SDK接入。
市面上也存在多款新生代的图数据库,为什么选择Neo4j进行研究试用呢?实际是在不太严谨的调研下,做出的尝试使用neo4j的决定:
- 当前若采用mysql或者mongo都无法快速满足当前需求(需要从多对多的网状关系中获取特定关系路径),虽然可曲线求国,但对于以后维护及使用不利
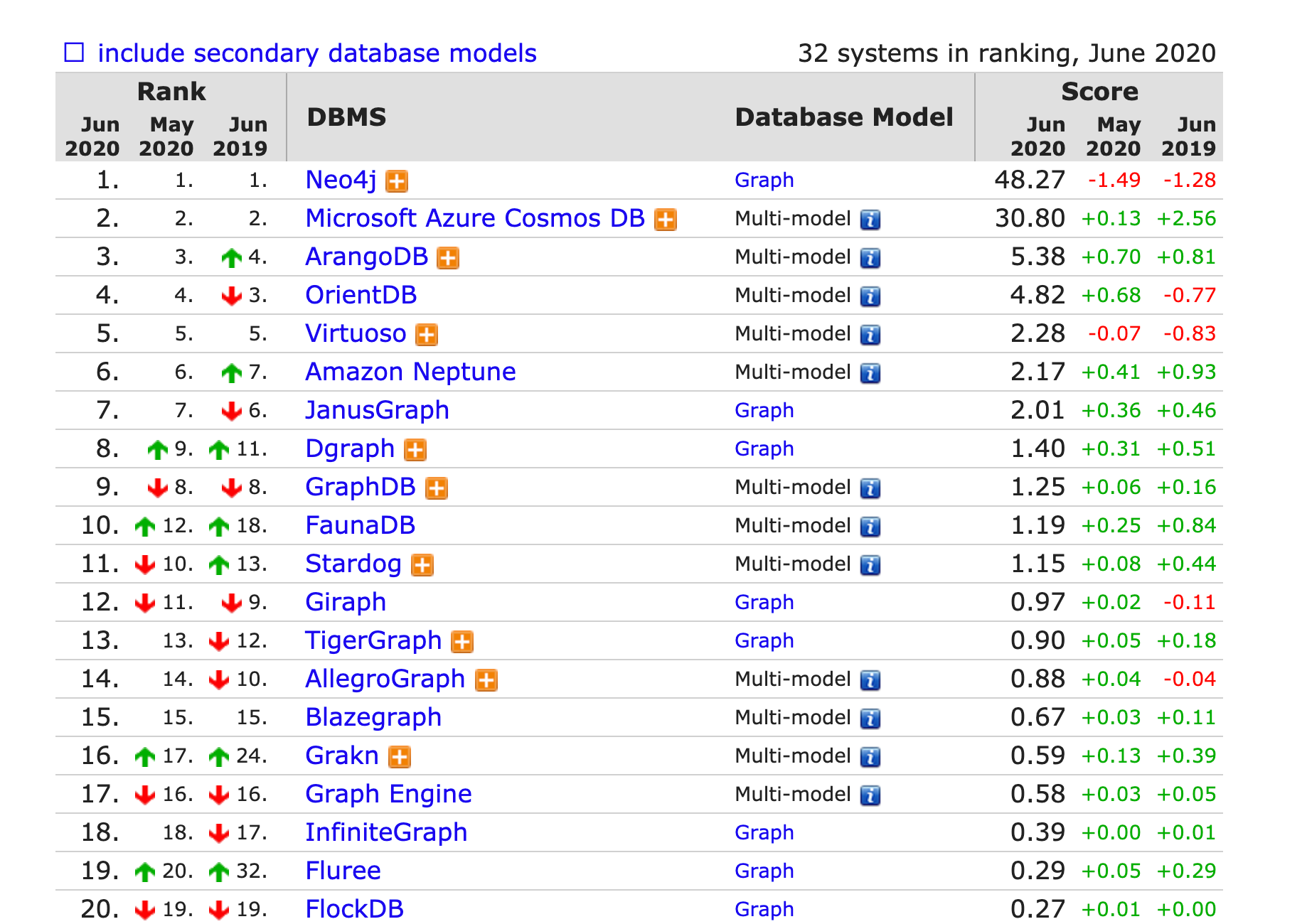
- Neo4j在图数据库排行上持续排名第一,仍是最流行的图数据库,使用基本功能满足当前需求
- 当前需要解决的问题数据量较少,长期处在万级的数量级上,但数据间存在复杂的网状依赖关系
- 使用环境为非生产环境,对可用性或可扩展性等要求不高
对于生产环境使用图数据库的情况,建议是根据具体需求做严谨的调研,以便保证选型的可靠。
附上当前图数据库的排行情况:
neo4j基础使用
安装neo4j:直接采用docker进行快速安装
1 | docker run -d -p 7474:7474 -p 7687:7687 --restart=always \ |
启动后,访问对应的web客户端即可访问neo4j,访问:http://192.168.1.181:7474,登录后即可使用Cypher语法进行相关的操作,以下是记录的一些基本操作:
1 | # 连接对应的数据库,URL地址: bolt://192.168.1.181:7687,及账号密码连接 |
上述操作所建立的图数据展示如下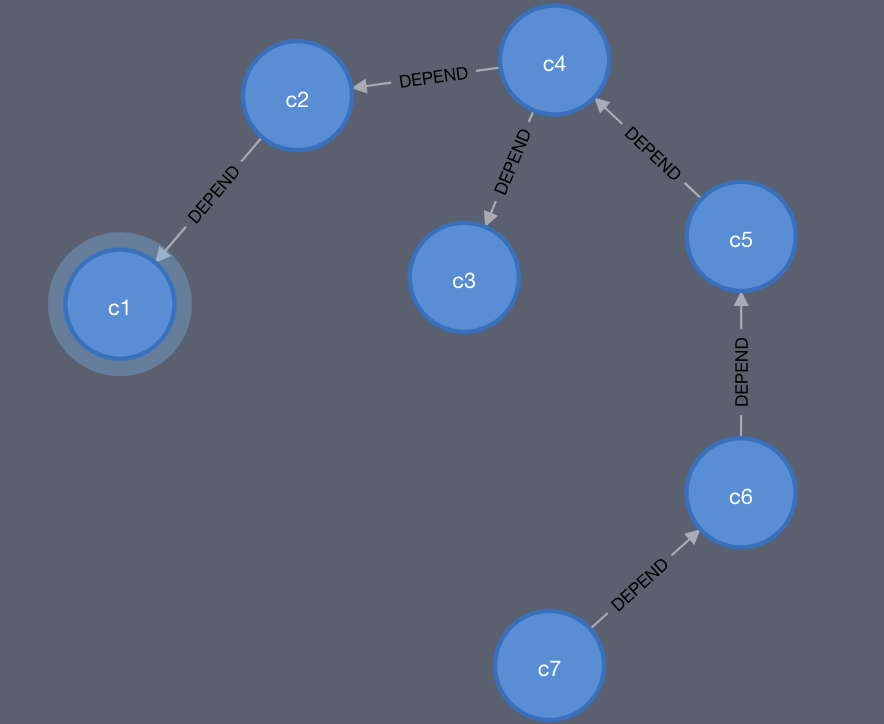
Python调用Neo4j
实际项目中使用Neo4j时,需要使用对应的库,对于python的项目可以使用官方的neo4j-python-dirver,也可是使用其官方成员所实现的py2neo库
安装py2neo库
1 | 当前最新release版为4.3.0,但4.3.0 存在不兼容neo4j v4版本的部分语法,因此采用修复了该问题的5.0b1 |
基础操作
1 | from py2neo import Graph |
Neo4j实际使用场景
前面把Neo4j的基础内容摸了一遍,还需要回归实际使用,去解决实际的问题。
而当前遇到的问题是:从接口用例的依赖关系中实时查询对应的用例的关联场景,以便在持续交付中通过场景进行自动化测试的调度
背景情况:当前的接口测试用例是以单个接口请求作为用例的最小粒度,而接口间的业务会存在相互依赖的动态数据(如订单流程中各接口的业务数据会依赖上游业务状态和返回数据),当前的解决方案是给对应的用例配置依赖前置用例解决业务状态依赖问题,通过局部变量或全局变量解决数据依赖问题,由于引用依赖是开放式的,因此用例间的依赖关系形成了网状的依赖关系,当前用例只知道它自身依赖谁,不清楚谁依赖它
解决方案: 采用Neo4j存储用例及用例间的依赖关系, 通过属性存储部分必要的用例属性,通过关系的查询可以灵活的获取目标场景数据
分步实施:
- Neo4j用例数据初始化: 将现有的用例及用例的关系全量同步到Neo4j中
- 同步维护Neo4j数据: 在用例新增/编辑时调用更新Neo4j的公共函数,同步更新Neo4j中数据和依赖关系
- 持续交付调度逻辑优化: 调度用例的逻辑修改成调度用例关联的目标场景,保证场景的闭环
- 用例详情展示实时关联场景: 在用例详情页通过Neo4j实时查询用例所对应的目标场景,提升用例场景维护的效率
- 实时场景列表数据维护: 新增对应的场景列表页,通过组合的场景数据去维护场景的用例级别,保证级别的有效性,并能快速了解不同模块的覆盖场景情况
实际效果:当前可通过一个Cypher的查询即可知道任意用例所关联的所有场景数据
1 | # 从neo4j中查询当前用例所关联的场景数据,并按关系数量排序,若有多个关联场景,取较短的作为目标场景 |
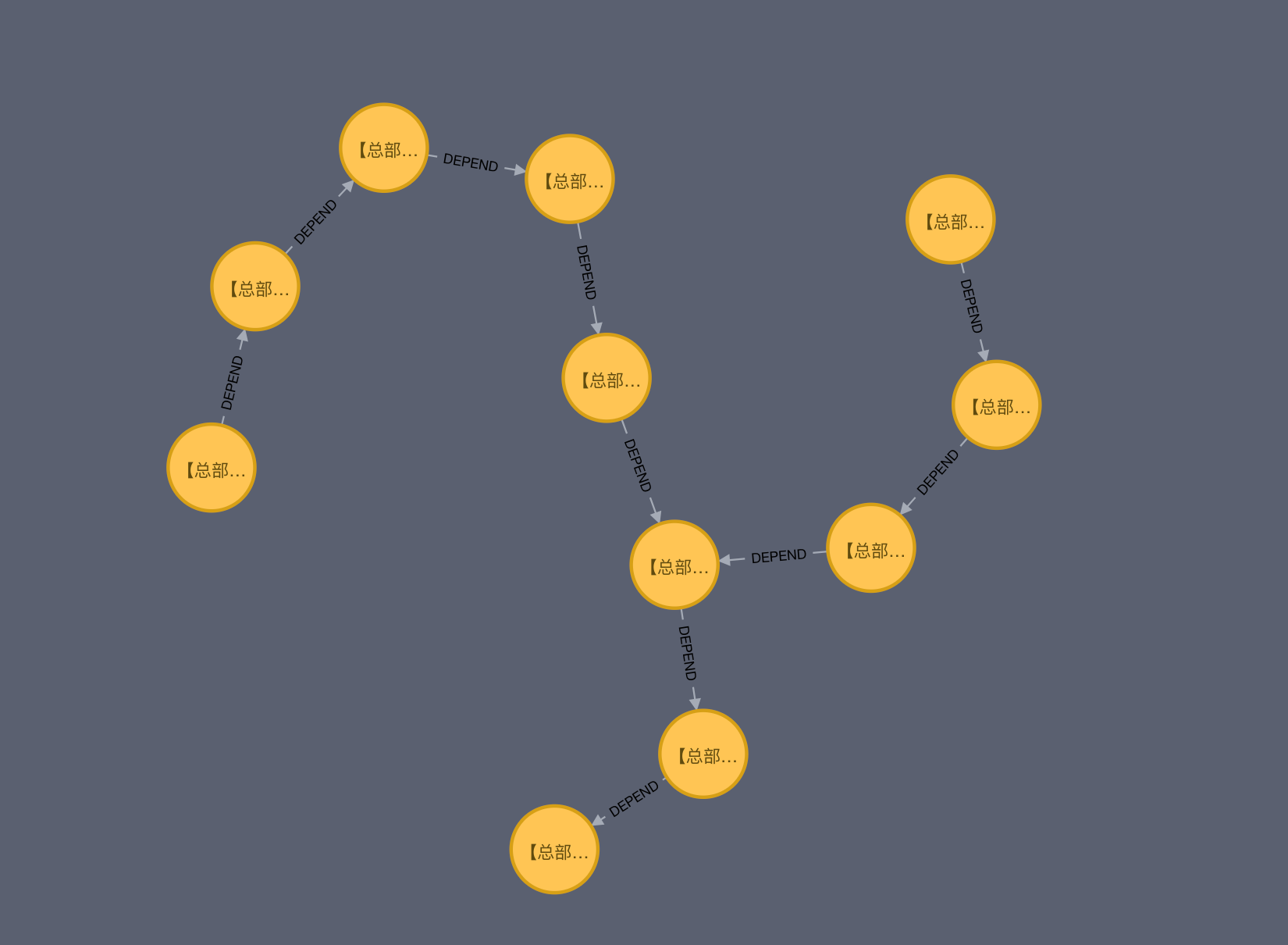
为了更加直观的展示对应的效果,可看下图展示图数据库中toB订单的用例间的关系图(来源Neo4j):

当需要从上述的数据中查找【总部】【客户订单】财务审核用例所属场景时,运行MATCH data=(:API_TEST_CASE)-[*0..]->(:API_TEST_CASE{name:'【总部】【客户订单】财务审核'}) RETURN data,即可获取下图所示的目标场景数据,最下面的为对应查询的节点,而上游有两个场景依赖了该用例,并且获取了整个依赖路径中的节点数据。该方式大大简化了获取关系信息的方式。
由于当前的应用场景较为简单,并且是在内部系统中使用,因此当前只是对neo4j的一次初步的探索实践,若需要进一步应用在业务系统中,得有明确的业务需求场景,然后再进行严谨的选型和规划。